sync once
sync.Once只有一个方法,sync.Do(),通常我们用来调用在多个地方执行保证只执行一次的方法,如初始化,关闭fd等 具体代码如下,通过atomic获取done,为0则抢锁执行do传进来的方法,执行完后将done atomic变成1
type Once struct {
done uint32
m Mutex
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 0 {
o.doSlow(f)
}
}
func (o *Once) doSlow(f func()) {
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}
sync.pool
主要为了减少gc,减少gc在mark的时候需要标记的inuse_objects数量过多。通俗点来说就是一个内存池,我们自己实现g et,put。
需要注意的是,仅存在与pool中,在外没有被其它地方引用,可能会被pool删除,下面我们来看看调用sync.Pool具体流程
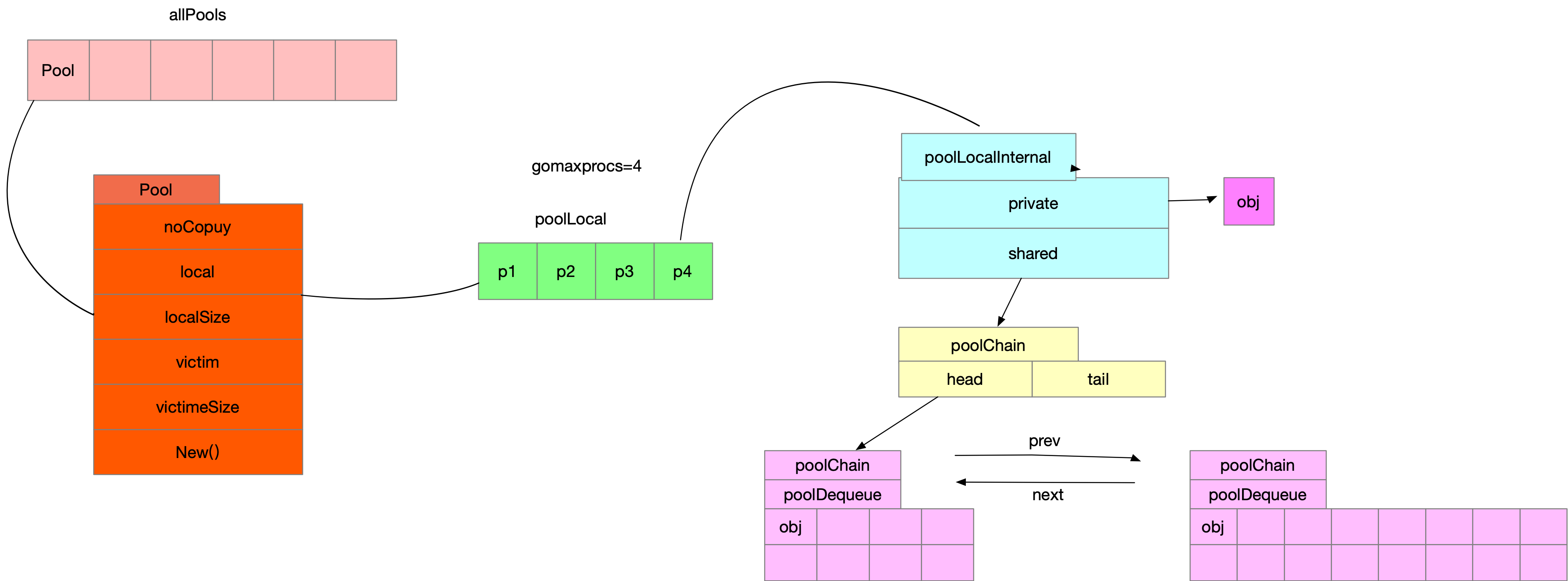
根据流程图我们先一起梳理下,所有的pool都被存储在allPools这个数组中,注意不要不停的生成新的sync.Pool,allPools是加锁去append
sync.pool init
pool的初始化调用的是pool.poolCleanup的方法,主要逻辑如下,将old里每个p清空,将allpools里p的local,localSize移动到victim,victimSize
然后将allpool移动给oldPools,方便后续清空
func poolCleanup() {
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
oldPools, allPools = allPools, nil
}
pool.get
现在我们来看看get的逻辑
- 通过调用pool.Get->pool.pin->pool.pinSlow获取一个poolLocal,具体代码如下
func (p *Pool) Get() any {
l, pid := p.pin()
}
func (p *Pool) pin() (*poolLocal, int) {
//获取pid,使g绑定p并禁止抢占(本地队列)
pid := runtime_procPin()
s := runtime_LoadAcquintptr(&p.localSize) // load-acquire
l := p.local // load-consume
//如果pid比我本地Pool.localSize小则直接返回
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
//生成新的poolLocal
return p.pinSlow()
}
func (p *Pool) pinSlow() (*poolLocal, int) {
//解除独占
runtime_procUnpin()
//加锁
allPoolsMu.Lock()
defer allPoolsMu.Unlock()
pid := runtime_procPin()
// poolCleanup won't be called while we are pinned.
s := p.localSize
l := p.local
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
//将poolLocal追加到allPools数组里
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
size := runtime.GOMAXPROCS(0)
//local根据p的个数设置数组长度
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
}
然后我们接着看后续逻辑
func (p *Pool) Get() any {
l, pid := p.pin()
//最优先元素,类似于p.runnext,或者cpu l1 缓存
x := l.private
l.private = nil
//如果没取到private
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
//去shared取,pool.local[pid].poolLocal.shared
x, _ = l.shared.popHead()
//shared没拿到,去别的pid里对应的poolLocal.shared偷一个
if x == nil {
x = p.getSlow(pid)
}
}
}
我们来看看从别的poolLocal获取内存具体的操作
func (p *Pool) getSlow(pid int) any {
size := runtime_LoadAcquintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
//从别的slow里偷
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
//在victim里找
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
//在victim里别的p上偷
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
// Mark the victim cache as empty for future gets don't bother
// with it.
atomic.StoreUintptr(&p.victimSize, 0)
//都没有返回nil
return nil
}
若果没有从getSlow上获取,还会调用pool.New,也就是我们sync.Pool{New:func}的方法,都拿不到则返回为nil
if x == nil && p.New != nil {
x = p.New()
}
return x
总结下,get的具体逻辑为
- 是否有Pool,没有则生成Pool并添加到runtime.allPools上
- 从Pool.poolLocal[pid].poolLocalInternal.private上拿,拿不到去shared上拿,还拿不到去别的pid上的shared拿
- 再拿不到从别的即将要被清空的Pool.victim上拿,逻辑如上,还拿不到则执行sync.Pool{New:func}。还拿不到则返回nil
pool.put
下面我们再来看看Pool.put,先放到Pool.poolLocal[pid].private,如果有值了,调用Pool.poolLocal[pid].shared.pushHead
pushHead里如果没值,则生成poolChainElt,且val长度为8,如果满了,则扩容,每次创建新的poolChainElt并扩容val长度都会*2,最大10亿多,并将新生成的
poolChainElt通过双向链表挂到之前的poolChainElt后面
// Put adds x to the pool.
func (p *Pool) Put(x any) {
if x == nil {
return
}
//获取一个[pid]poolLocal
l, _ := p.pin()
//[pid]poolLocal.poolLocalInternal.Private为空则赋值
if l.private == nil {
l.private = x
} else {
//放[pid]poolLocal.poolLocalInternal.shared.head上
l.shared.pushHead(x)
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
}
}
//l.shared.pushHead(x)
func (c *poolChain) pushHead(val any) {
d := c.head
//head为空则生成一个poolChainElt,且val为8长度的双向链表节点
if d == nil {
// Initialize the chain.
const initSize = 8 // Must be a power of 2
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
storePoolChainElt(&c.tail, d)
}
//放入节点的head
if d.pushHead(val) {
return
}
//没放入成功,满了 则生成下一个链表节点,并将节点容量并乘2
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// Can't make it any bigger.
newSize = dequeueLimit
}
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(&d.next, d2)
//扩容后重新放入
d2.pushHead(val)
}
sync gc部分
同上sync.pool.init 将Pool.local移动到Pool.victim ,将Pool.localSize移动到Pool.victimSize并将上一次的Pool.victim,Pool.victimSize清空
lock 锁实现基础
锁的定义如下,先看下state字段,sema后文会详细介绍
// src/sync/mutex.go
type Mutex struct {
//32位 前29位表示有多少人g等待互斥锁的释放,后三位分别为mutexLocked,mutexWoken,mutexStarving
state int32
//信号量 对应在src/runtime/sema.go上的semTabSize存储,挂着等待锁的g
sema uint32
}
- mutexLocked表示是否已经加锁 1为已加锁
- mutexWoken 表示从正常模式被从唤醒
- mutexStarving 进入饥饿模式
锁正常模式和饥饿模式
正常模式下,锁是先入先出,排队获取锁,新唤醒的g与新创建的g竞争时(这时候占有cpu),大概率拿不到锁,go里面解决办法是出现超过1ms没拿到锁的g,锁进入饥饿模式
饥饿模式下,互斥锁会直接交给等待队列最前面的g,新的g直接丢在队尾,且不能自旋(没有cpu片)
取消条件为队尾的g获取到了锁,或者当前g获取锁1ms内
加锁逻辑
加锁逻辑,如果状态位是0,则改成1然后加锁成功,如果已经有锁的情况下,进入m.lockSlow()逻辑
// src/sync/mutex.go
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
如果当前不能加锁,则进入自旋等模式等待锁释放,大体流程如下
- 通过runtime_canSpin判断是否能进入自旋
- 运行在多 CPU 的机器上
- 当前g获取锁进入自旋少于4次
- 至少有个p runq为空
- 通过自旋等待互斥锁的释放
- 计算互斥锁的最新状态
- 更新互斥锁的状态并获取锁
func (m *Mutex) lockSlow() {
//省略自旋获取锁代码
//通过信号量保证只会有一个g获取到锁,也就是我们开头的Mutex.sema
runtime_SemacquireMutex(&m.sema, queueLifo, 1)
}
下面我们看看信号量的逻辑,了解完信号量后接着分析runtime_SemacquireMutex
信号量详解
信号量的存储方式如下图,全局一个semtable,semtable是一个251长度的数据,每一个数组元素根据&m.sema hash后,用二叉树存储
比如lock A addr=1,lock b addr = 252,根据hash后,都在semtable[1]里,用树存储,而等待锁lock A的所有的g都通过sudog用
waitlink连接,具体结构图如下
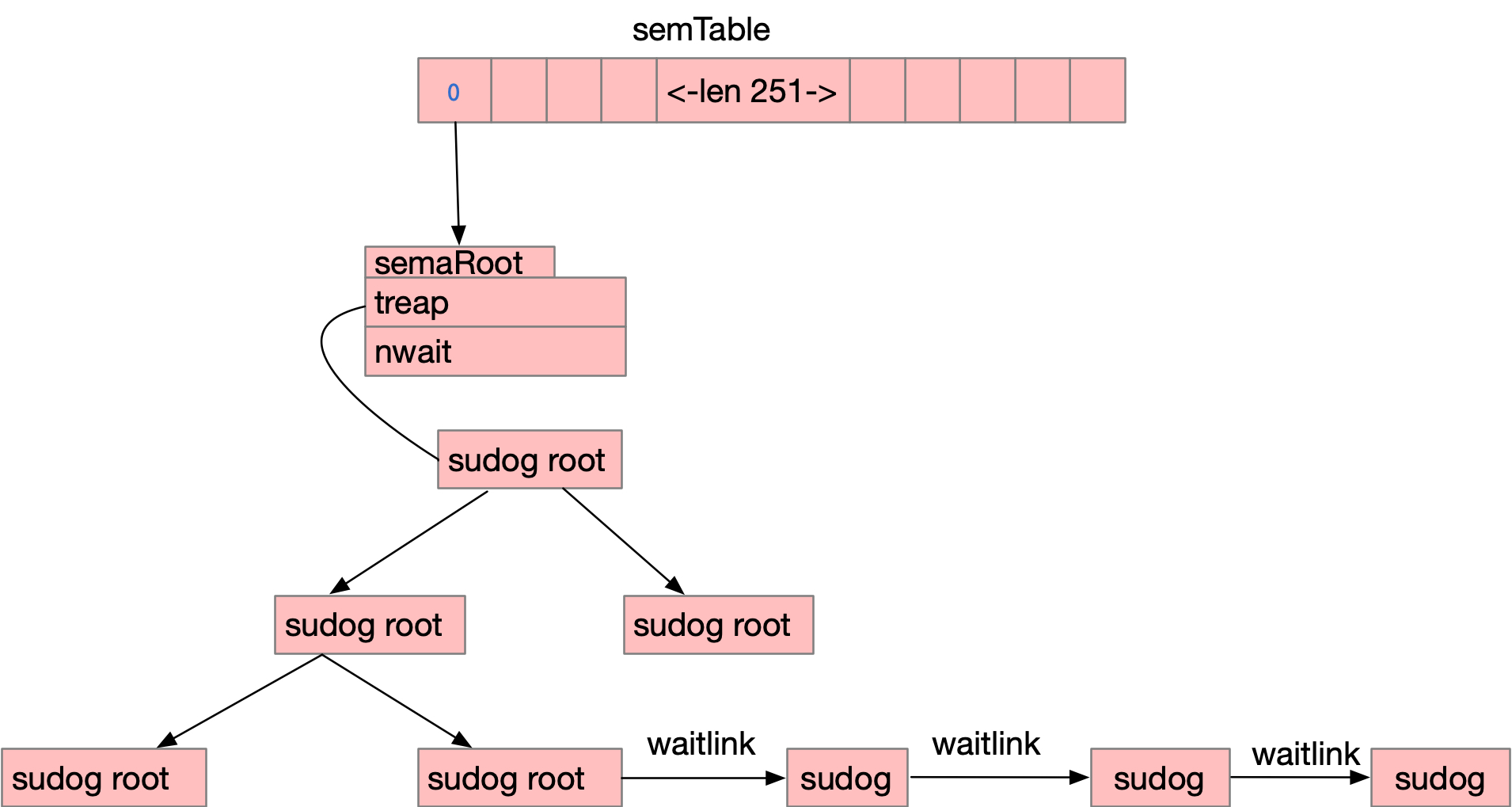 下面我们接着看
下面我们接着看runtime_SemacquireMutex函数
//runtime_SemacquireMutex()->semacquire1()
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int, reason waitReason) {
//获取当前的g
gp := getg()
//获取一个sudog
s := acquireSudog()
//通过地址hash得到二叉树跟目录
root := semtable.rootFor(addr)
for {
lockWithRank(&root.lock, lockRankRoot)
//root上等待锁的sudog的个数
root.nwait.Add(1)
if cansemacquire(addr) {
root.nwait.Add(-1)
unlock(&root.lock)
break
}
//找到该addr在树上对应的节点
root.queue(addr, s, lifo)
//阻塞gopark,解锁的时候goready恢复
goparkunlock(&root.lock, reason, traceEvGoBlockSync, 4+skipframes)
if s.ticket != 0 || cansemacquire(addr) {
break
}
}
releaseSudog(s)
}
信号量解锁详解
具体代码与加锁的信号量处理差不多,简略代码如下,有兴趣的可以看看原来代码
// src/runtime/sema.go
func semrelease1(addr *uint32, handoff bool, skipframes int) {
readyWithTime(s, 5+skipframes)
}
func readyWithTime(s *sudog, traceskip int) {
if s.releasetime != 0 {
s.releasetime = cputicks()
}
goready(s.g, traceskip)
}
读写锁RWMutex
我们依次分析获取写锁和读锁的实现原理
type RWMutex struct {
w Mutex // 复用读写锁
writerSem uint32 // 写等待读信号量
readerSem uint32 // 读等待写信号量
readerCount atomic.Int32 // 执行的读操作数量
readerWait atomic.Int32 // 写操作被阻塞时等待的读操作个数
}
写锁
复用mutex锁,分几种情况
- 已有写锁,rw.w.Lock()将会阻塞,上文mutex逻辑,同时将readerCount设置最小值
- readerCount有值,说明有读锁,调用runtime_SemacquireRWMutex休眠,等待读锁释放writerSem信号量
func (rw *RWMutex) Lock() {
rw.w.Lock()
r := rw.readerCount.Add(-rwmutexMaxReaders) + rwmutexMaxReaders
if r != 0 && rw.readerWait.Add(r) != 0 {
runtime_SemacquireRWMutex(&rw.writerSem, false, 0)
}
}
读锁
readerCount为负数(-1<<30),则说明有写锁
直接调用runtime_SemacquireRWMutexR,如果有写锁,会阻塞readerSem
如果该方法的结果为非负数,则通过信号量readerSem阻塞,后续等待Unlock解写锁唤醒

func (rw *RWMutex) RLock() {
if rw.readerCount.Add(1) < 0 {
// A writer is pending, wait for it.
runtime_SemacquireRWMutexR(&rw.readerSem, false, 0)
}
}